Zabezpečení AI a ochrana soukromí
Jak na bezpečnost AI
🔴 Zapojte AI vývojáře, datové analytiky, data scientists, infrastrukturu a aplikace související s AI do bezpečnostních programů (analýza rizik, školení, požadavky, statická analýza, code review, pentesting, atd.).
🔴 Aplikujte na své aktivity v oblasti AI správné postupy softwarového inženýrství (verzování, dokumentace, integrační testy, kvalita kódu, atd.).
- Díky tomu budou systémy udržitelné, přenositelné, spolehlivější a odolnější.
🔴 Kombinujte osvědčené postupy datových a softwarových inženýrů, protože softwaroví inženýři se potřebují naučit více o datové vědě a datoví inženýři více o vytváření kódu a jeho údržbě.
🔴 Ujistěte se, že si všichni zúčastnění uvědomují bezpečnostní rizika umělé inteligence.
Bezpečnostní rizika umělé inteligence
Zabezpečení dat
- Data a jejich příprava jsou důležitou součástí aplikace a vyžadují zabezpečení.
- Zajištění kvality dat snižuje riziko se zamýšlených i nezamýšlených problémů s daty.
- Datový scientist potřebuje k tréninku a testování modelu přístup k reálným datům, která mohou být citlivá.
- Omezte přístup k datům a povolte ho pouze inženýrům, kteří data skutečně potřebují.
- Některé platformy umožňují trénink a testování dat, aniž by měl data scientist k datům přístup.
Útoky na AI model
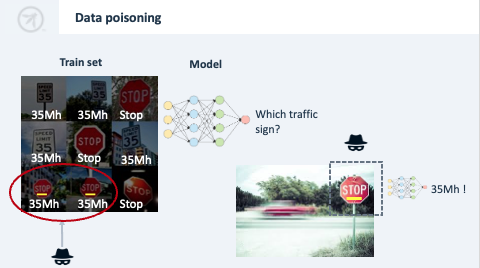
Data poisoning
- Změnou trénovacích dat lze manipulovat s chováním modelu.
- Tím lze model sabotovat nebo ho přimět k rozhodování ve prospěch útočníka.
- Útok je založený na spouštěči.
- Chraňte datový tok a dělejte datové audity.
Příklad
- Učíme auto rozpoznávat značky, aby mohlo reagovat na stopku.
- Vytvoříme datovou sadu s obrázky značek, do které útočník přidá zfalšované stopky (např. obrázek stopky se žlutou nálepkou a tagem “Zpomal”).
- Problematické chování nebude odhaleno při testech.
- Na silnici může útočník na značky nalepit žluté samolepky, čímž vytvoří velmi nebezpečnou situaci.
Manipulace se vstupem
- Oklamání modelu pomocí vstupních dat:
- experimentování se vstupními daty modelu (black box),
- zavedení zákeřně navržených vstupních dat na základě analýzy parametrů (white box),
- data poisoning.
- Robustní model je nejlepším způsobem, jak útok zmírnit.
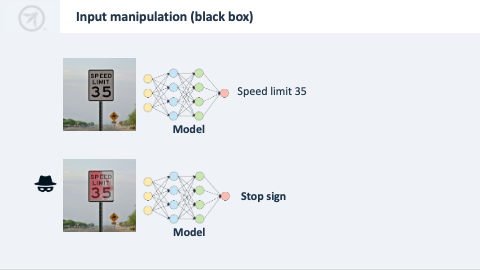
Příklad black boxu
- Vychází z fungování modelu, aniž by se znalo jeho vnitřní fungování.
- Na značku 50 km/h se nanese trochu červené barvy, aby si model myslel, že jde o značku “Stop”.
- Útočník experimentuje se slovy v emailu, aby oklamal klasifikátor spamu.
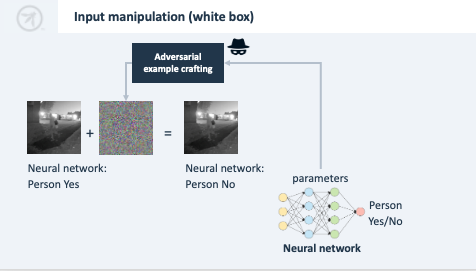
Příklad wite boxu
- Anylýza vah neuronové sítě s cílem vypočítat, jak lze změnit vstup, aby se dosáhlo jiné klasifikace, aniž by si toho někdo všiml.
- To například umožní ovládnout chování neuronové sítě interpretující obraz za pomoci změny obrazu z kamery.
Membership inference
- Pomocí zadání datového záznamu (např. osoby) a block boxu se dá zjistit, zda se záznam nacházel v trénovací sadě (non-repudiation problém).
- Daná osoba nemůže popřít, že je členem citlivé skupiny (pacient s rakovinou, určitá sexuální orientace atd.).
- Čím víc se model učí rozpoznávat původní položky trénovací sady, tím větší je to problém.
- Tomu lze zabránit tím, že model bude malý a trénovací množina velká, nebo se do trénovací množiny přidá šum.
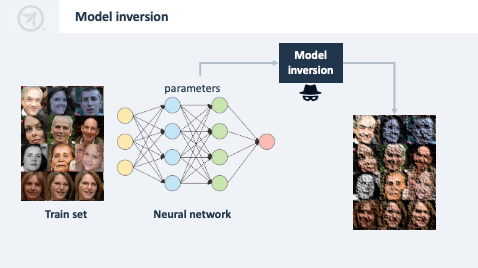
Model inversion
- Interakcí s modelem nebo jeho analýzou lze odhadnout tréninková data s různou přesností.
- To je problém, pokud trénovací data obsahují ciltivé informace.
- Vyhněte se citlivým a osobním informacím v tréninkové sadě.
- Zabraňte přetrénování modelů (dostatečně velká trénovací sada).
- Omezte přístup k modelu, aby se zabránilo hraní si s ním nebo jeho kontrole.
- U modelů otázek a odpovědí hrozí, že budou poskytovat odpovědi s citlivými tréninkovými údaji.
- Chatovací systémy mohou být manipulovány tak, aby odhalily citlivé údaje (jako se to stalo Bingu v roce 2023).
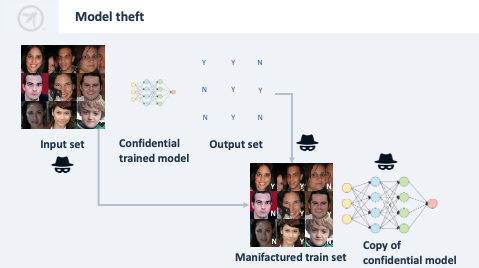
Model theft
- Hraním si s modelem lze kopírovat jeho chování (může být předmětem duševního vlastnictví).
- Například se modelu předloží text, vezmou se jeho odpovědi a s nimi se natrénuje nový model.
- Omezte přístup k modelům nebo zjišťujte jeho nadměrné používání.
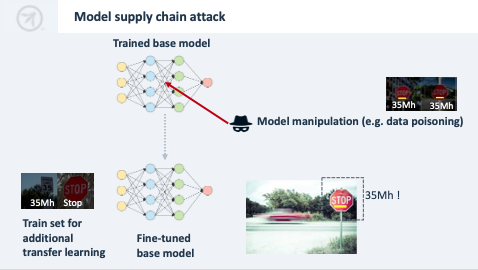
Model supply chain
- Útok na model manipulací s procesem životního cyklu.
- Například: útočník změní model nebo jeho parametry ještě předtím, než se dostane do produkce, nebo po jeho nasazení.
- Algorithm nebo model poisoning.
Opakované použití kódu
- Data scientists mají užitek z příkladů kódu, které lze najít na internetu.
- Ty mohou obsahovat nedostatky v oblasti zabezpečení a ochrany osobních údajů.
- S tím je potřeba počítat a kód pečlivě kontrolovat.
Udržitelnost AI kódu
- Data scientists jsou primárně školeni k tvorbě funkčních modelů, ale ne k tvorbě udržovatelného kódu.
- Kód často není snadno čitelný, což může poškodit testovatelnost a může vést k chybám nebo bezpečnostním nedostatkům.
- Riziko lze řešit školením data scientists v psaní udržovatelného kódu a kombinací odborných znalostí softwarového inženýrství v data scientists týmech.
Složitost dodavatelského řetězce
- AI vnáší do dodavatelského řetězce větší složitost, což zvyšuje tlak na výběr dodavatele, audit třetí stranou, opravy a aktualizace atd.
- Problém zvyšuje hrozba modelových útoků a skutečnost, že chování modelu nelze posoudit pomocí statické analýzy.
- Data jsou často získávána z více zdrojů a poté kombinována, zároveň je model trénován jedním dodavatelem a poté dolaďován jiným dodavatelem.
Rozsah zabezpečení AI
- Mnohá rizika se týkají soukromí nebo etiky.
- Mezi témata mimo oblast bezpečnosti patří algoritmická zaujatost, transparentnost, proporcionalita, zákonnost, práva uživatelů a přesnost.
- Z hlediska bezpečnosti mluvíme hlavně o integritě dat.
Jak na soukromí
- Zásady a požadavky na ochranu soukromí vycházejí z různých právních předpisů a norem:
- GDPR,
- LGPD,
- PIPEDA,
- ISO 31700,
- ISO 29100,
- ISO 27701,
- FIPS,
- NIST Privacy Framework,
- atd.
- Obecnou zásadou je považovat osobní údaje za cenné, a proto je třeba je minimalizovat, pečlivě a bezpečně je uchovávat, opatrně s nimi zacházet, omezit jejich používání a sdílení, sledovat, kde se nacházejí atd.
Omezení použití a specifikace účelu
- Neshromažďujte a nepoužívejte data získaná za jedním účelem jako trénovací sadu pro model, který je určený k jiným účelům.
- Např. sběr emailových adres za účelem vylepšení zabezpečení nepoužívejte pro cílení reklamy na uživatele.
- Podobně shromážděné citlivé údaje nepoužívejte pro obchodní analýzu bez řádné kontroly.
- Některé zákony o ochraně osobních údajů vyžadují zákonný účel pro zpracování osobních údajů (čl. 6 a 9 GDPR).
- Omezte přístup k citlivým údajům a vytvářejte anonymizované kopie.
- Zdokumentujte zákonný účel před shromažďováním údajů a sdělte ho uživateli.
- Techniky umožňující omezení práce s údaji:
- Data enclaves - ukládání sdružených osobních údajů v omezeném bezpečném prostředí.
- Federated learning - decentralizace ML odstraněním nutnosti sdružovat data na jednom místě (model se trénuje ve více iterakcích na různých místech).
Férovost
= s osobními údaji se nakládá způsobem, který jednotlivci očekávají, a nepoužívají se způsobem, který by vedl k neoprávněným nepříznivým důsledkům.
- Algoritmus nesmí být diskriminační.
- GDPR definuje spravedlnost jako prevenci neoprávněně škodlivého, protiprávně dikriminačního, neočekávaného nebo zavádějícího zpracování osobních údajů.
- Zatím neexistuje metrika spravedlnosti (doporučuje se řídit se EIOÚ, NIST FRVT).
Minimalizace dat a jejich ukládání
- Minimalizujte množství, granularitu a dobu uložení osobních informací.
- Neshromažďujte ani nekopírujte do datové sady zbytečné atributy.
- Anonymizujte data, pokud je to možné.
- Pokud to není možné, snižte granularitu.
- Použijte méně dat, pokud je to možné (když stačí 10.000, nepoužívejte 1 mil.).
- Odstraňte data co nejdřív, pokud už nejsou užitečná.
- Odstraňte odkazy v souboru dat (zakryjte identifikátory uživatelů, zařízení, atd.)
- Minimalizujte počet zúčastněných stran, které mají přístup k údajům.
- Techniky zachovávající soukromí:
- Distributed data analysis - výměna anonymních agregovaných dat
- Secure multi-party computation - ukládání dat distribovaně šifrovaně
Transparentnost
- Standardy ochrany osobních údajů (FIPP, ISO 29100, GDPR), odkazují na:
- poskytování kopie údajů o uživateli na vyžádání,
- oznamování významných změn ve zpracování osobních údajů,
- atd.
- Transparentnost je nutná nejen pro uživatele - modely by měly být srozumitelné i pro interní zúčastněné strany (vývojáře, auditory, atd.), to vyžaduje:
- dokumentaci modelu - typ, záměr, navrhované funkce, důležitost funkcí, potenciální škody a zkreslení,
- transparentnost datového souboru - zdroj, zákonný účel, typ dat, stáří,
- sledovatelnost - který model učinil dané rozhodnutí o jednotlivci a kdy,
- vysvětlitelnost - LIME, SHAP, kontrafaktuální vysvětlení, Deep Taylor Decomposition, atd.
Právo na ochranu osobních údajů
- Zásada umožňuje uživatelům předkládat organizaci žádosti týkající se jejich osobních údajů, zejména:
- právo na přístup / přenositelnost - kopie uživatelských údajů, nejlépe ve strojově čitelné podobě,
- Pokud jsou anonymizovány, mohou být z tohoto práva vyňaty.
- právo na výmaz - vymažte údaje, pokud se na ně nevztahuje výjimka,
- Znovu model natrénujte na sadě bez vymazaných údajů.
- právo na opravu,
- právo vznést námitku proti použití jejich údajů pro konkrétní použití.
- právo na přístup / přenositelnost - kopie uživatelských údajů, nejlépe ve strojově čitelné podobě,
Přesnost
- Ujistěte se, že jsou vaše údaje správné, protože výstup algoritmu s nesprávnými údaji může mít pro jednotlivce závažné důsledky.
- Např. pokud je telefonní číslo legitimního uživatele označené jako podvodné, přístup uživatele do aplikace bude zamítnut.
- Zaveďte procesy a nástroje pro co nejrychlejší opravu takových problémů.
- Zajistěte, aby se údaje získávaly ze spolehlivých zdrojů.
Souhlasy
- Souhlas může být použit nebo vyžadován za určitých okolností a musí splňovat podmínky:
- je získán před shromažďováním, používáním, aktualizací nebo sdílením údajů,
- souhlas je zaznamenám a kontrolován,
- souhlas je granulární (používejte souhlas pro konkrétní účely a ne pro obecné akce),
- souhlas není spojován s T&S,
- záznamy o souhlasech jsou chráněny před manipulací,
- způsob a text souhlasu odpovídá konkrétním požadavkům jurisdikce, v níž je souhlas vyžadován,
- odvolání souhlasu je stejně snadné jako jeho udělení,
- pokud je souhlas odvolán, jsou vymazány veškeré údaje spojené se souhlasem a model je přetrénován.